Uniform Resource Locator
A URL is a way to show where to find a certain resource. Most of the time you will find URLs when looking for webpages. Like http://www.example.com/home.htm. If you would access this URL your browser would try to download the resource home.htm.
DNS Name or IP Address?
Most of the time you will see URLs with DNS names like
google.comand your device will perform name resolution with the help of DNS to find the IP Address you can also use the IP address directly subce it makes no difference. However be careful since some websites don’t accept connections when they are not directed at their hostname (see here)
A URL has different parts that are shown here:
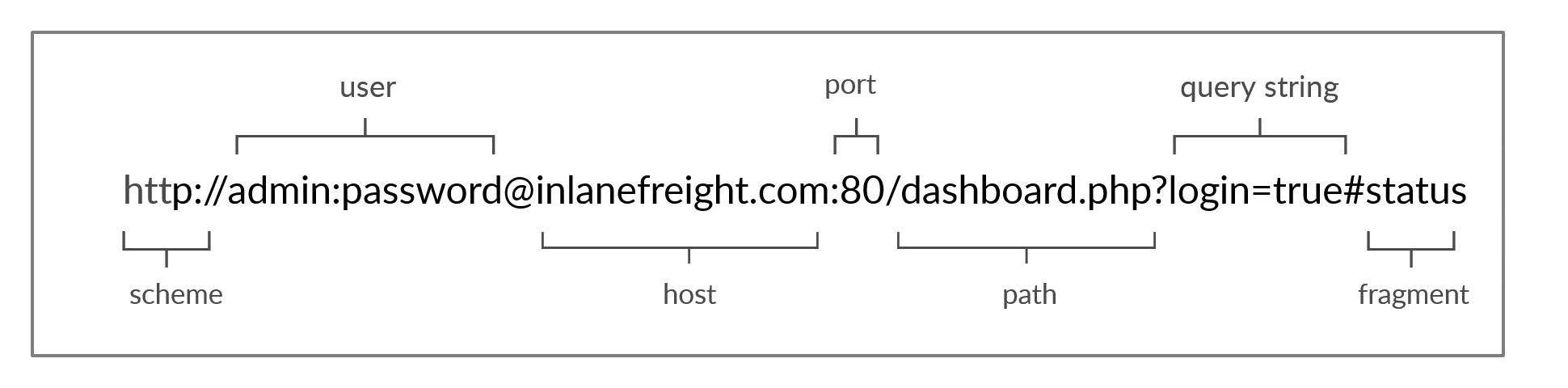 Not all of these parts are needed and some of them are set by default like the
Not all of these parts are needed and some of them are set by default like the port for HTTP URLs will always be assumed to be 80 and for HTTPS URLs 443. Depending on what, where and how you want to access it, the URL will change. For example if you want to access the same server but instead of using the HTTP Protocol you want to use the FTP protocol you would change the scheme of the URL to ftp://. The user part is pretty self-explanatory.
The host is part tells the browser which server you want to access you can do this by specifying the DNS name of the server or the IP Address the user part just indicates what credentials to use if authentication is needed. The path is the path to the file that you want to access or modify. The query string will send the values inside to the webserver inside an HTTP Request. And the fragment in the end will just move you to a specific part of the webpage.
Now, of course some of these things don’t apply to every Protocol that uses URLs but remember that the core structure always stays the same, especially the scheme, the host and the path. For example this is how an LDAP URL might look like:
ldap://example.com:1389/something
What to look out for?
One thing that can help when trying to find vulnerabilities on a website is looking at the URL. One good example is the LFI vulnerability. If you see any URL that has a file name inside it is totally worth checking out. Here an example:
http://www.example.cpm/?file=homepage.htm